

OKD 4, but again.
| 8 minute read
I wish I wrote more stuff down.
I’ve been at this since before I woke up. I accidentally killed my OKD4 cluster earlier in the summer, and I want it back. I made the terrible mistake of not looking over the configs before just re-running the setup scripts, and now I’ve been sitting at my computer for 6 hours and two cups of coffee with NOTHING TO SHOW FOR IT. :D
So, we’ve got the Bind Configs from last time, they look correct. I installed them, they give me the answers, but NO AUTHORITY. That is the only thing that seems amiss, and my cluster won’t ignite. I’m going to try it a 4th time and see if I can somehow get logs this time.
I should see if I can work out how to make my router do the DNS. PFSense has DNS features, and apparently, someone has gotten them to work before. CSH has DNS servers that I got working for them. I think that if this was a real cluster, I should definitely see if I can just use my PfSense rig to do all this Bind nonsense for me.
I mean, logically, as long as I can get the correct answers for everything, then there shouldn’t be a problem, authority or not. I fear that maybe, the server just has to be up for long enough to become an authority or something?
If/when this current installation fails, I need to collect logs and see if it’ll provide any hints. I’m pretty goddamn confused right now. I hoped this was going to be an easy process, but obviously I was wrong. Now, I’m invested enough that I don’t feel bad sinking even more time into this.
INFO Waiting up to 20m0s for the Kubernetes API at https://api.okd4.postave.us:6443...
INFO API v1.19.2-1008+70708036fc2657-dirty up
INFO Waiting up to 30m0s for bootstrapping to complete...
https://github.com/W0827 15:04:41.460975 29020 reflector.go:326] k8s.io/client-go/tools/watch/informerwatcher.go:146: watch of *v1.ConfigMap ended with: very short watch: k8s.io/client-go/tools/watch/informerwatcher.go:146: Unexpected watch close - watch lasted less than a second and no items received
E0827 15:04:47.890906 29020 reflector.go:153] k8s.io/client-go/tools/watch/informerwatcher.go:146: Failed to list *v1.ConfigMap: Get "https://api.okd4.postave.us:6443/api/v1/namespaces/kube-system/configmaps?fieldSelector=metadata.name%3Dbootstrap&limit=500&resourceVersion=0": EOF
ERROR Cluster operator authentication Degraded is True with IngressStateEndpoints_MissingSubsets::OAuthServiceCheckEndpointAccessibleController_SyncError::OAuthServiceEndpointsCheckEndpointAccessibleController_SyncError: OAuthServiceEndpointsCheckEndpointAccessibleControllerDegraded: oauth service endpoints are not ready
IngressStateEndpointsDegraded: No subsets found for the endpoints of oauth-server
OAuthServiceCheckEndpointAccessibleControllerDegraded: Get "https://172.30.77.63:443/healthz": dial tcp 172.30.77.63:443: i/o timeout (Client.Timeout exceeded while awaiting headers)
INFO Cluster operator authentication Progressing is Unknown with NoData:
INFO Cluster operator authentication Available is False with OAuthServiceCheckEndpointAccessibleController_EndpointUnavailable::OAuthServiceEndpointsCheckEndpointAccessibleController_EndpointUnavailable: OAuthServiceEndpointsCheckEndpointAccessibleControllerAvailable: Failed to get oauth-openshift enpoints
OAuthServiceCheckEndpointAccessibleControllerAvailable: Get "https://172.30.77.63:443/healthz": dial tcp 172.30.77.63:443: i/o timeout (Client.Timeout exceeded while awaiting headers)
INFO Cluster operator csi-snapshot-controller Progressing is True with _Deploying: Progressing: Waiting for Deployment to deploy csi-snapshot-controller pods
INFO Cluster operator csi-snapshot-controller Available is False with _Deploying: Available: Waiting for Deployment to deploy csi-snapshot-controller pods
ERROR Cluster operator etcd Degraded is True with EnvVarController_Error::InstallerController_Error::RevisionController_ContentCreationError::ScriptController_Error::StaticPods_Error: EnvVarControllerDegraded: at least three nodes are required to have a valid configuration
StaticPodsDegraded: pods "etcd-fedora" not found
InstallerControllerDegraded: missing required resources: [configmaps: etcd-scripts,restore-etcd-pod, configmaps: config-1,etcd-metrics-proxy-client-ca-1,etcd-metrics-proxy-serving-ca-1,etcd-peer-client-ca-1,etcd-pod-1,etcd-serving-ca-1, secrets: etcd-all-peer-1,etcd-all-serving-1,etcd-all-serving-metrics-1]
ScriptControllerDegraded: "configmap/etcd-pod": missing env var values
RevisionControllerDegraded: configmaps "etcd-pod" not found
INFO Cluster operator etcd Progressing is True with NodeInstaller: NodeInstallerProgressing: 1 nodes are at revision 0; 0 nodes have achieved new revision 1
INFO Cluster operator etcd Available is False with StaticPods_ZeroNodesActive: StaticPodsAvailable: 0 nodes are active; 1 nodes are at revision 0; 0 nodes have achieved new revision 1
INFO Cluster operator ingress Available is False with IngressUnavailable: Not all ingress controllers are available.
INFO Cluster operator ingress Progressing is True with Reconciling: Not all ingress controllers are available.
ERROR Cluster operator ingress Degraded is True with IngressControllersDegraded: Some ingresscontrollers are degraded: ingresscontroller "default" is degraded: DegradedConditions: One or more other status conditions indicate a degraded state: DeploymentAvailable=False (DeploymentUnavailable: The deployment has Available status condition set to False (reason: MinimumReplicasUnavailable) with message: Deployment does not have minimum availability.), DeploymentReplicasMinAvailable=False (DeploymentMinimumReplicasNotMet: 0/2 of replicas are available, max unavailable is 1)
ERROR Cluster operator insights Degraded is True with PeriodicGatherFailed: Source config could not be retrieved: certificatesigningrequests.certificates.k8s.io is forbidden: User "system:serviceaccount:openshift-insights:gather" cannot list resource "certificatesigningrequests" in API group "certificates.k8s.io" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "cluster-reader" not found, configmaps is forbidden: User "system:serviceaccount:openshift-insights:gather" cannot list resource "configmaps" in API group "" in the namespace "openshift-config": RBAC: clusterrole.rbac.authorization.k8s.io "cluster-reader" not found, customresourcedefinitions.apiextensions.k8s.io "volumesnapshots.snapshot.storage.k8s.io" is forbidden: User "system:serviceaccount:openshift-insights:gather" cannot get resource "customresourcedefinitions" in API group "apiextensions.k8s.io" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "cluster-reader" not found, hostsubnets.network.openshift.io is forbidden: User "system:serviceaccount:openshift-insights:gather" cannot list resource "hostsubnets" in API group "network.openshift.io" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "cluster-reader" not found, pods is forbidden: User "system:serviceaccount:openshift-insights:gather" cannot list resource "pods" in API group "" at the cluster scope: RBAC: clusterrole.rbac.authorization.k8s.io "cluster-reader" not found
INFO Cluster operator insights Disabled is False with AsExpected:
ERROR Cluster operator kube-apiserver Degraded is True with NodeInstaller_InstallerPodFailed: NodeInstallerDegraded: 1 nodes are failing on revision 9:
NodeInstallerDegraded:
INFO Cluster operator kube-apiserver Progressing is True with NodeInstaller: NodeInstallerProgressing: 1 nodes are at revision 0; 0 nodes have achieved new revision 10
INFO Cluster operator kube-apiserver Available is False with StaticPods_ZeroNodesActive: StaticPodsAvailable: 0 nodes are active; 1 nodes are at revision 0; 0 nodes have achieved new revision 10
INFO Cluster operator monitoring Available is False with :
INFO Cluster operator monitoring Progressing is True with RollOutInProgress: Rolling out the stack.
ERROR Cluster operator monitoring Degraded is True with UpdatingconfigurationsharingFailed: Failed to rollout the stack. Error: running task Updating configuration sharing failed: failed to retrieve Prometheus host: getting Route object failed: the server could not find the requested resource (get routes.route.openshift.io prometheus-k8s)
INFO Cluster operator openshift-apiserver Available is False with APIServices_PreconditionNotReady: APIServicesAvailable: PreconditionNotReady
INFO Cluster operator operator-lifecycle-manager-packageserver Available is False with :
INFO Cluster operator operator-lifecycle-manager-packageserver Progressing is True with : Working toward 0.16.1
INFO Use the following commands to gather logs from the cluster
INFO openshift-install gather bootstrap --help
FATAL failed to wait for bootstrapping to complete: timed out waiting for the condition
Oh wait, hold on…
Ya know, I’m also using some older versions of both CoreOS and OKD. Maybe I should update those and try this again.
So I tried using the latest OKD and the latest Fedora. (Fedora 34.20210808.3.0 and OpenShift 4.7.0-0.okd-2021-08-22-163618). That didn’t work, because for some reason the signature was missing when I tried igniting the bootstrapper. I dialed it back a few versions to 34.20210711.3.0. That didn’t work either, for similar reasons, so I just went back to what was there (That was Fedora 32.20201104.3.0) and… that worked! And what’s more, I didn’t need an Authority section showing up in my DNS! All I needed was to ensure the DNS entries showed up, and specify non-static DHCP information (IP Address, Default Route, Mask, Nameserver, etc (Look at ignite.sh)) and then presto! We’re back in business! OKD is up and running again!
Oh my god, Kubernetes is just magic.
One thing I noticed was that Fedora CoreOS 32 updated to Fedora CoreOS 34 during this process. Kinda interesting, and convenient!
So once that was set up, I had to wait for all the clusteroperators to come up. But once that was done, I needed to set up my NFS share so that the registry had storage to use. That was pretty easy, since I had already installed and configured NFS. Then, I needed to use a registry_pv.yaml file from Craig to create the binding in the cluster.
Once that was done, I needed to get authentication working. I messed up a bit on this and lost the password, but I managed to start over by deleting my secrets using oc delete secret secret/<secret_name> and then just followed Craig’s guide to do it properly. (Protip, use history -d <command_no> to remove commands, ya know, for when you store your password in plaintext in .bash_history :))
And… that’s just about where I’m at. The cluster was still busy updating… for some reason (and there seems to be some issue with retrieving an update :/)
More on that later. It looks like an issue with Monitoring.
Failed to rollout the stack. Error: running task Updating Prometheus-k8s failed: waiting for Prometheus object changes failed: waiting for Prometheus openshift-monitoring/k8s: expected 2 replicas, got 1 updated replicas
I guess I’ll give it a day to see if it figures itself out. This is not a production cluster, so it’s probably not a huge deal if one or two things are busted.
This was fun, despite the slight amount of existential dispair it inflicted upon me earlier today. Also might I mention how messed up it is that simply waiting 10 months completely broke the install process? Of course, that might not have been the issue, but I’m blaming that…. and the DNS. I’m going to be making some updates to my okd4-utils repo.
As always, important links include…
Craig’s Install Guide: https://itnext.io/guide-installing-an-okd-4-5-cluster-508a2631cbee
Christian’s Blog Post: https://cloud.redhat.com/blog/openshift-4-bare-metal-install-quickstart
And this new GitHub issue that may be worth looking into for configuration purposes (mostly because xdotool requires X11): https://github.com/openshift/okd/issues/27
So anyway, my plan: To add one or two things onto this cluster and then, you guessed it:
Continue working on ShelfLife.
I am so tired of this project not existing. I want it to exist.
One day later
So, this is a bit wack:
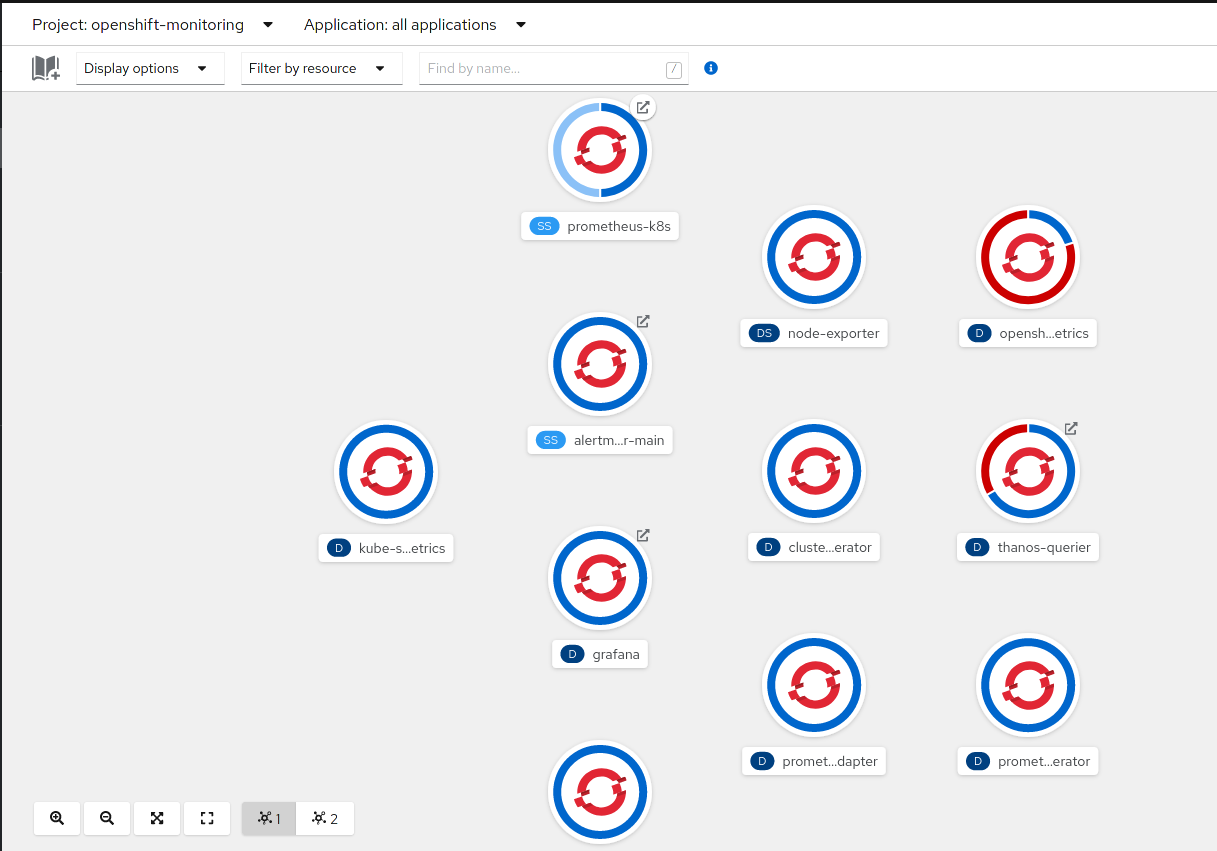
Looks like there are a few failed services that might be preventing the second Prometheus pod from coming up. I tried deleting the prometheus pod to see if it’d figure itself out, but it didn’t. So I’m gonna try deleting the failed pods and see what happens.
After some bumps and bruises, the auxiliary pods are back. But prometheus still isn’t scaling up. Highly wack. I don’t really feel like dealing with this right now. Oh well.
Until next time!